— Les avantages de la « longue traîne » des données des projets Ontario Historical County Map Project et Don Valley Historical Mapping Project
La plupart des universitaires qui ont écrit sur les SIG historiques ont discuté du coût élevé de la construction de projets SIGH (Gregory et Ell, 2007). La construction d’un projet SIG est un effort couteux. Cependant, peu ont mentionné les avantages de la nature continue ou de la durée prolongée de certains projets et des avantages à long terme des données issues des projets. Le Ontario Historical County Map Project (OCMP) et le Don Valley Historical Mapping Project (DVHMP) sont deux projets qui ont profité de la « longue traîne » de leur existence afin de continuer à développer et à exploiter des applications utiles ainsi que d’utiliser des données historiques construites depuis longtemps (ou en cours de construction).
Le OCMP a été conçu quelques années après la publication du célèbre Canadian County Atlas Project aux bibliothèques de l’Université McGill à la fin des années 1990. Les cartes de comté du XIXe siècle ont généralement été publiées plus tôt que les atlas de comté. Le projet Atlas se concentre uniquement sur les cartes liées et l’OCMP se concentre uniquement sur les cartes antérieures de grand format. Toutefois, comme le projet Atlas, le County Map Project vise principalement à permettre d’interroger les noms des occupants des terrains figurant sur les cartes et d’afficher les noms sur les images des cartes historiques.
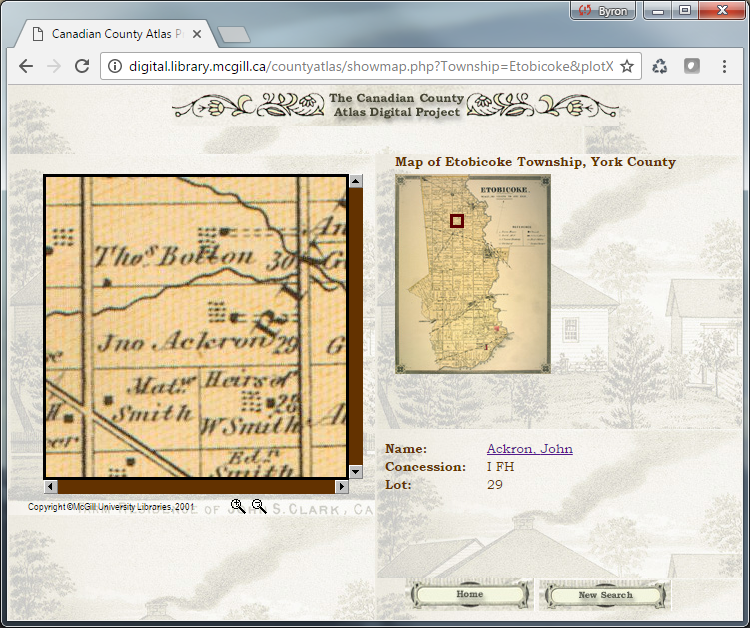
Bien que le projet de McGill n’utilise pas de technologie SIG pour afficher des informations sur les noms, il a profité de la technologie Web pour faire la mise en page des images des atlas et de la programmation PHP pour lier les emplacements d’images dans la base de données des noms des propriétaires fonciers. Le projet Atlas nous a certainement inspirés dans l’élaboration du Ontario Conunty Map Project.
Contrairement au projet Atlas, l’OHCMP a été un projet SIG dès le début. Cependant, comme pour le projet Atlas, nous voulions également veiller à ce que les utilisateurs du County Map Project puissent bénéficier de la technologie Web pour visualiser les cartes et les données SIG. Étant une base de données SIG, une nouvelle méthode de diffusion devait être utilisée.
Les tests préliminaires de la technologie Web étaient « pré-Google » et utilisaient ce qui est maintenant un logiciel archaïque de cartographie Web. Lors de notre première tentative en 2004, nous avons utilisé ArcIMS (Internet Map Server) d’Esri, mis à notre disposition dans le cadre de notre licence de campus avec Esri Canada. Nous avons chargé notre base de données entière dans ArcIMS qui, à l’époque, était composée uniquement des comtés de Waterloo et Brant. À notre surprise, nous avons pu construire un outil de requête sophistiqué et avons réussi à afficher les cartes de comtés numérisées et géoréférencées sur l’application en ligne.
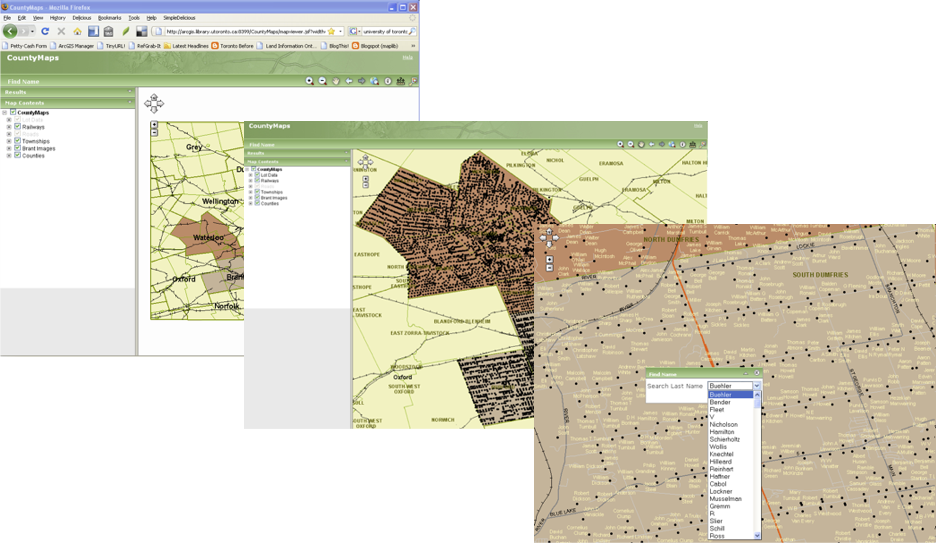
Tout en produisant des résultats relativement impressionnants pour l’époque (si quelqu’un était suffisamment patient pour attendre les résultats d’une requête ou d’un zoom in ou d’un zoom out), il était clair que cette configuration était moins idéale, car le logiciel était extrêmement difficile à installer, très lent à rendre les résultats et nous a donné des difficultés à trouver un espace serveur adéquat sur lequel installer en permanence le logiciel. En raison des limitations des logiciels disponibles, la partie du projet qui consistait à développer une carte Web avec les noms des occupants fonciers a été mise en veilleuse. Bien sûr, Google Maps a changé l’ensemble du paysage de la cartographie Web en 2005. Bien que beaucoup aient adopté Google Maps pour afficher leurs données sur le Web, nos tentatives ont été entravées par la grande taille de notre base de données des occupants. Alors que, à l’époque, MySQL était souvent utilisé pour travailler avec le PHP et Google API, la conversion de notre base de données géospatiale en une base de données MySQL aurait été un recul dans le développement SIG du projet.
D’autres tentatives plus récentes d’utilisation de la technologie de cartographie Web en 2013 incluaient également une configuration Mapserver avec OpenLayers et une base de données géospatiale PostgreSQL utilisant PostGIS. Bien que les données shapefile devaient être converties en PostGIS, cette configuration a au moins permis la maintenance de notre base de données dans un environnement SIG, contrairement à l’utilisation de MySQL. La carte Web qui en a résulté était très prometteuse, mais nécessitait un peu de codage et de manipulation. N’ayant aucun programmeur dans l’équipe ou aucun fonds pour en embaucher un, la programmation de l’application était limitée à un congé de recherche de six mois et aux rares journées tranquilles à la Map and Data Library. Sans un programmeur, il était clair qu’il ne s’agissait pas d’une solution idéale et qu’il faudrait des années pour terminer le projet.
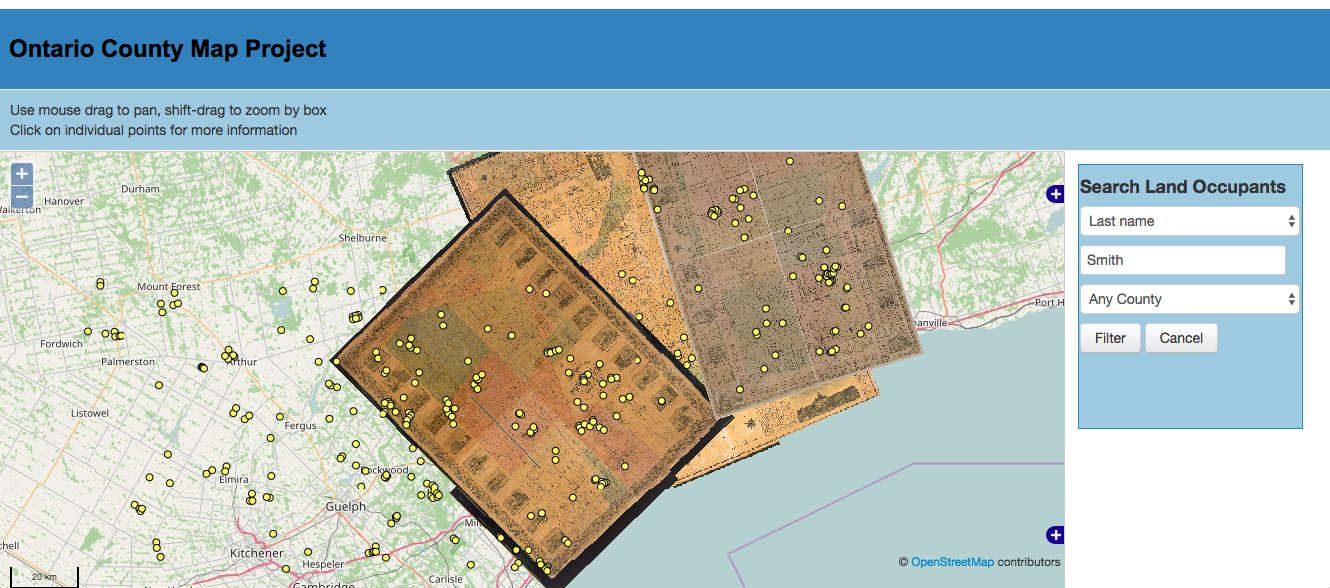
Pendant de nombreuses années, j’ai ignoré ArcGIS Online que je considérais comme un projet très lourd d’Esri pour des projets moins ambitieux. Je me demandais comment on pouvait construire un outil en ligne avec des fonctionnalités SIG et amener les gens à s’y intégrer. Cependant, sa popularité a grandi tellement parmi nos utilisateurs de l’Université de Toronto que j’ai finalement eu besoin d’apprendre à l’utiliser pour pouvoir offrir du support technique. Quelle meilleure façon de m’enseigner comment utiliser ArcGIS Online que d’y verser les données du projet County Map Project? À ma grande surprise, ArcGIS Online n’était pas seulement amusant et plein de fonctionnalités en SIG et cartographie Web, il a également implanté l’application Web AppBuilder. Outre des dizaines de modèles StoryMaps, Web AppBuilder vous permet de rendre vos données SIG dans une interface Web où vous pouvez ajouter des widgets personnalisables qui fonctionnent très bien, même dans les navigateurs mobiles. Être capable d’interroger ou filtrer les 80 000 noms de notre base de données a été un critère clé pour l’adoption de toute technologie Web pour le projet. ArcGIS Online répond à ce critère fondamental, et a également permis le rendu d’images de haute résolution des cartes de comté numérisées. La facilité d’utilisation et la personnalisation des applications Web sans programmation sont également de bons points de vente. D’autres widgets amusants et utiles incluent l’utilisation de lignes de temps animées des données et d’un outil de navigation qui permet de visualiser deux ensembles de données l’une par-dessus l’autre et de glisser une barre d’outils pour basculer entre les affichages.
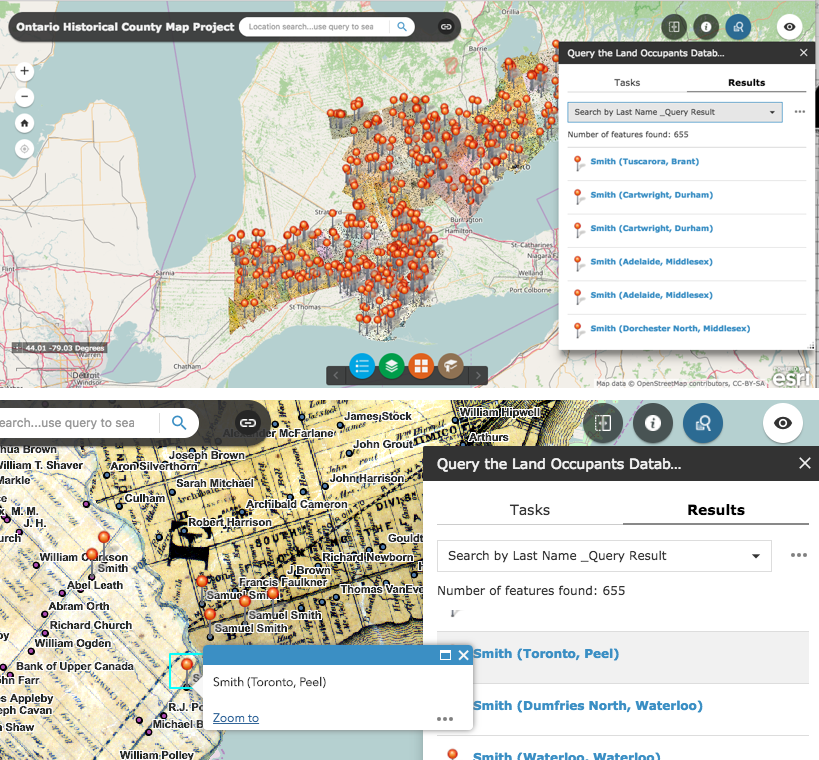
Adopter ArcGIS Online en tant qu’outil de cartographie Web a permis au projet d’être présenté au public où les utilisateurs peuvent effectivement profiter des données construites au cours des 15 dernières années. Je n’ai jamais pensé que nous aurions une solution de cartographie Web avant de terminer la base de données, mais dans l’ensemble, je suis très content de la plupart des fonctionnalités de l’application Web à ce stade, car notre base de données continue de croître et nous continuons à compiler plus de noms de propriétaires fonciers à partir des cartes de comté historiques. Fait intéressant, pendant l’écriture de ce billet, j’ai reçu trois messages sur le projet et des demandes d’informations supplémentaires auprès des utilisateurs du site de County Maps. Sans mettre nos données à disposition de cette manière, je doute que notre projet ait attiré tant d’attention.
Inspiré par notre succès avec l’outil de création d’applications Web, j’ai décidé de créer une application pour le DVHMP et j’ai constaté que les données que nous avions construites il y a plus de sept ans ont vraiment pris vie sur le Web. Être capable d’interroger les données et de rendre les données de polygone et de point ensemble dans une vue sur le Web est motivant.
ArcGIS online n’est évidemment pas le seul outil qui a profité de la cartographie web et des avancées de l’informatique « en nuage » pour permettre aux utilisateurs de créer leurs propres applications de cartographie web. Les produits tels que Mapbox augmentent également en popularité en raison de leur facilité d’utilisation, de leurs fonctionnalités puissantes et personnalisables ainsi que de l’attrait du produit cartographique final.
La cartographie Web existe depuis les années 1990, mais avec de nouvelles technologies avancées de cartographie Web comme ArcGIS online et Mapbox, il est peut-être temps pour de nombreux autres ensembles de données SIGH inactifs ou longtemps oubliés d’être retirés des disques durs et des clés USB et leur redonner une nouvelle vie en les affichant dans des cartes Web créées facilement. Je suis ravi de penser à voir éventuellement les données de Montréal Avenir du Passé, par exemple, rendues disponibles en les affichant sur une carte Web pour que tout le monde puisse interagir avec elles.
Le Partenariat canadien SIGH étudie de nombreux outils de cartographie Web et des méthodes de visualisation. Nous travaillons également avec Esri Canada, dans le cadre du projet GeoHist, pour fournir des exigences SIGH spécifiques aux outils de cartographie en ligne. Avec les composants puissants déjà disponibles dans ArcGIS online, Mapbox et d’autres outils de cartographie web, l’avenir de la cartographie web pour les SIGH est très intéressant et accessible à toute personne intéressée à les développer sans avoir à coder.
Références :
Gregory, Ian., et Paul S. Ell. Historical GIS: Technologies, Methodologies, and Scholarship. New York: Cambridge University Press, 2007.