Liens rapides:
Carte web de démonstration utilisant un logiciel libre (Mapbox, JQueryUI):
Historical Atlas of Canada Online Learning Project (HACOLP) :Croissance démographique, densité et répartition – par division de recensement, 1851 à 1961
http://mercator.geog.utoronto.ca/georia/mapbox-hacolp
Carte web de démonstration utilisant ArcGIS Online:
HACOLP : Densité de population par division de recensement, 1851-1961, applications sensibles au temps (3 versions)
HACOLP : Croissance de la population par division de recensement 1851-1961 applications sensibles au temps
http://hgisportal.esri.ca/portal/apps/MapAndAppGallery/index.html?appid=f7e6329dd6b3494b9b689e1750cf6781
Pour des documents détaillés sur le développement des projets pilotes, voir les liens à la fin de cet article.
TL’Atlas historique du Canada est un projet de recherche et de publication en trois volumes, terminé en 1993, qui utilise des cartes, du texte et d’autres documents graphiques pour explorer des thèmes de l’histoire du Canada. Une sélection de planches thématiques de l’Atlas a été publiée en ligne en 2008 à l’aide de la technologie ArcIMS d’Esri, dans le cadre du Historical Atlas of Canada Online Learning Project (HACOLP). Pour plus d’informations sur ce projet, voir: http://www.historicalatlas.ca/website/hacolp/about.htm
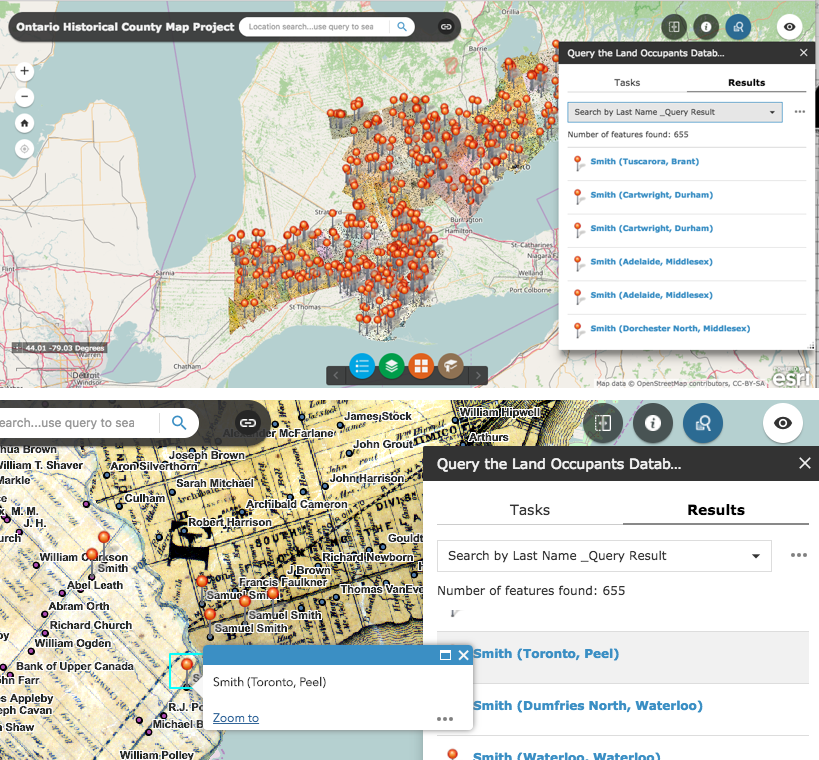
L’un des principaux thèmes abordés dans l’Atlas a été l’évolution rapide de la population à travers le pays au cours du siècle précédent 1961, année qui marque la fin de la période couverte dans l’Atlas. Un certain nombre de mesures démographiques ont été utilisées pour différentes cartes, périodes et sous-régions, mais quand le HACOLP a été mis en place, il a été décidé de créer un chapitre intitulé Summary of Population Growth, 1851-1961 qui permettrait aux utilisateurs de voir comment le changement s’est produit pendant toute cette période, mettant en relation trois représentations cartographiques différentes.
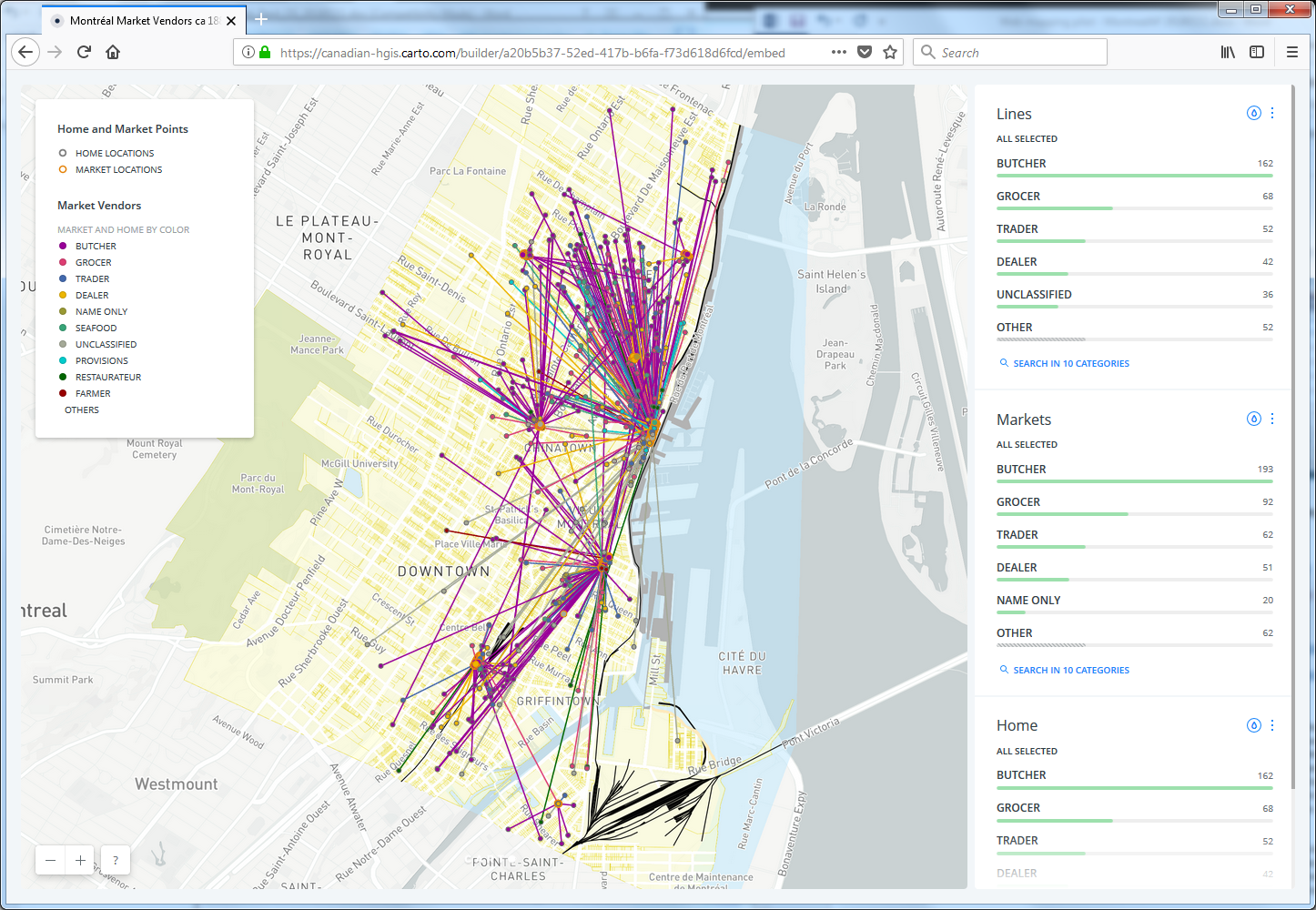
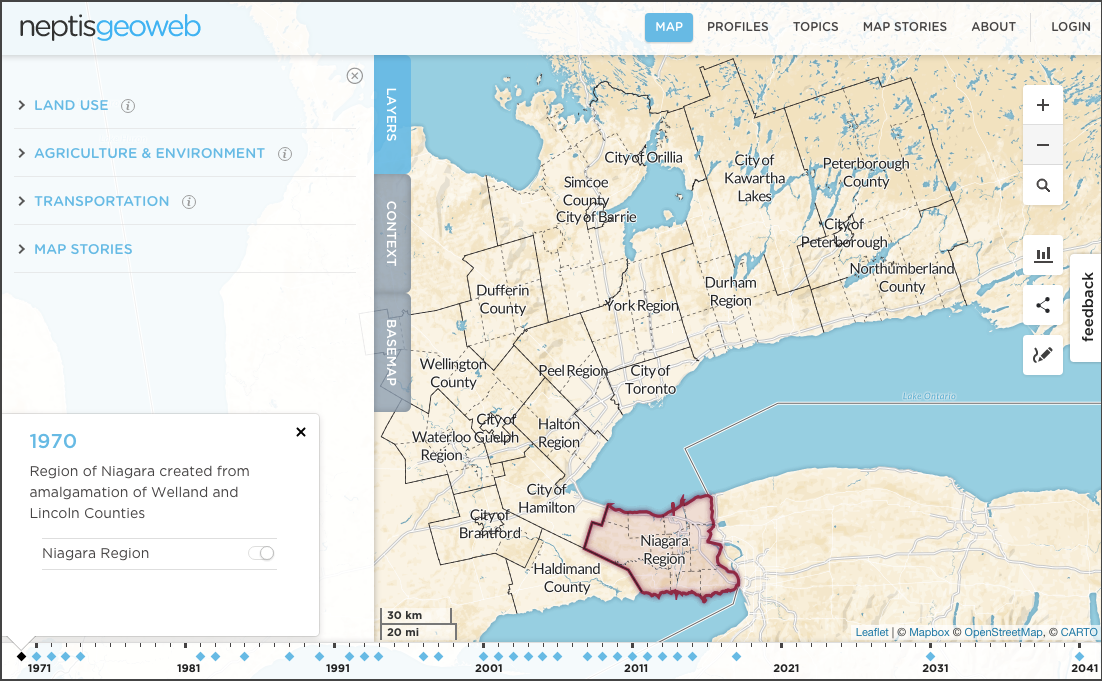
Le site web original présentait trois cartes interactives de la population par division de recensement, utilisant trois méthodes de symbolisation différentes: densité de population (choroplèthe), croissance démographique (cercles gradués) et répartition de la population (densité de points) pour onze recensements canadiens, 1851 à 1961. Ces cartes utilisaient la technologie ArcIMS et une légende JavaScript personnalisée utilisant des cases à cocher pour afficher ou masquer chaque année.
Le but de ce projet pilote était de créer de nouvelles cartes web pour rajeunir et améliorer les cartes originales, en performance et en visualisation. À l’aide des données fournies par HACOLP, les cartes ont été reproduites pour ce projet pilote tout en étant mises à jour selon les normes actuelles de cartographie web et en mettant en place un curseur de temps pour visualiser chaque période de recensement afin de remplacer les cases à cocher. Ce projet était également approprié pour explorer la capacité du logiciel de cartographie web selon sa flexibilité de conception des légendes et pour les projections cartographiques autres que le Web Mercator standard.
Comme prévu pour ce projet, nous avons conçu et produit deux versions différentes pour chacun de ces thèmes : l’une utilisant la plateforme ArcGIS Online et l’autre utilisant un logiciel libre et des outils de service web, dans ce cas, nous avons utilisé principalement les bibliothèques Mapbox et JQueryUl javascript.
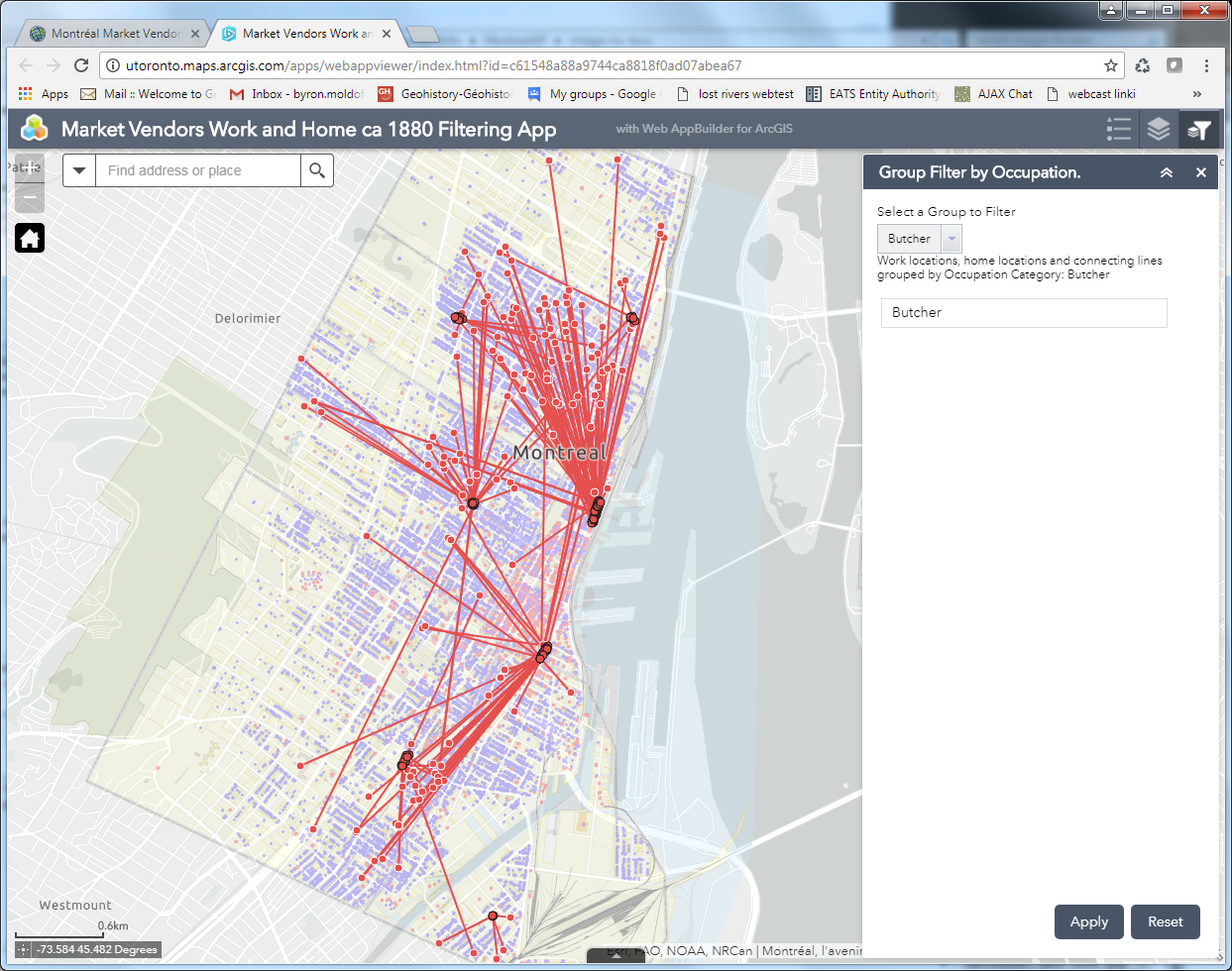
Les VERSIONS EN LIGNE d’ArcGIS se trouvent sur le portail de développement Geohistory-Géohistoire Canada (techniquement un portail ArcGIS Entreprise) hébergé en ligne par nos partenaires d’Esri Canada à HACOLP Population Apps Gallery. Pour voir le contenu d’un autre portail, allez à: http://hgisportal.esri.ca/portal/home. La « Galerie » contient 4 applications : une pour la croissance démographique (cercles gradués) et trois versions de la densité de la population (choroplèthe) – une avec une projection Web Mercator, une autre avec une projection Lambert Conic Conformal et la troisième utilisant une configuration qui génère des cartes en mosaïque à la volée – à des fins de comparaison des performances. Nous avons également créé une version de l’application pour tester la procédure Optimize Layers », disponible dans ArcGIS Online, mais pas dans l’environnement du portail. Ces méthodes comparatives sont expliquées dans le document de développement détaillé ArcGIS Online (voir le lien ci-dessous) – vous pouvez les visualiser pour comparer leur performance pour vous-même. La version Lambert met en évidence la capacité de projections alternatives dans ArGIS Online, qui sont plutôt faciles à réaliser. D’un autre côté, la cartographie par densité de points n’était pas facile à réaliser en utilisant les outils disponibles.
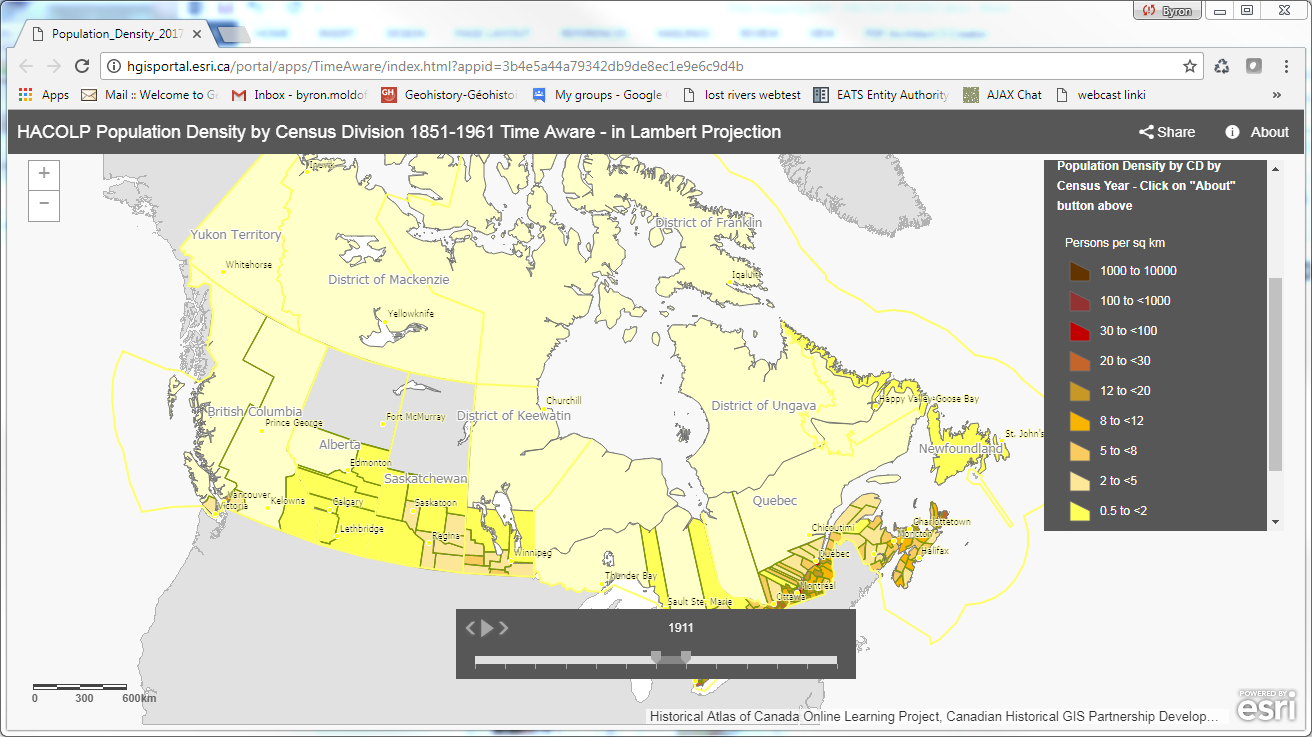
Les version Mapbox des cartes HACOLP sont hébergées sur un serveur du département de géographie de l’Université de Toronto. Nous avons été en mesure de générer des cartes pour les trois types de représentations en utilisant Mapbox. Toutefois, il ne prend pas en charge les projections autres que le Web Mercator. Les cartes ont été placées dans une seule page d’accueil affichant des images de chaque carte avec des liens vers les cartes interactives. Elles peuvent être trouvées ici : http://mercator.geog.utoronto.ca/georia/mapbox-hacolp.
Mapbox est une plateforme de cartographie en ligne et libre (open source) pour la conception de cartes personnalisées. Les cartes sont créées à partir de mosaïques d’images vectorielles et ont développé ce format, « [traduction] une approche avancée de la cartographie où les données sont livrées à l’appareil et précisément rendues en temps réel » (www.mapbox.com/maps). Les mosaïques vectorielles fournissent une version vectorielle de la technologie de pavage d’images que Google a utilisé pour révolutionner les performances de cartographie web. Esri et d’autres leaders de l’industrie utilisent maintenant des tuiles vectorielles pour leur cartographie de base.
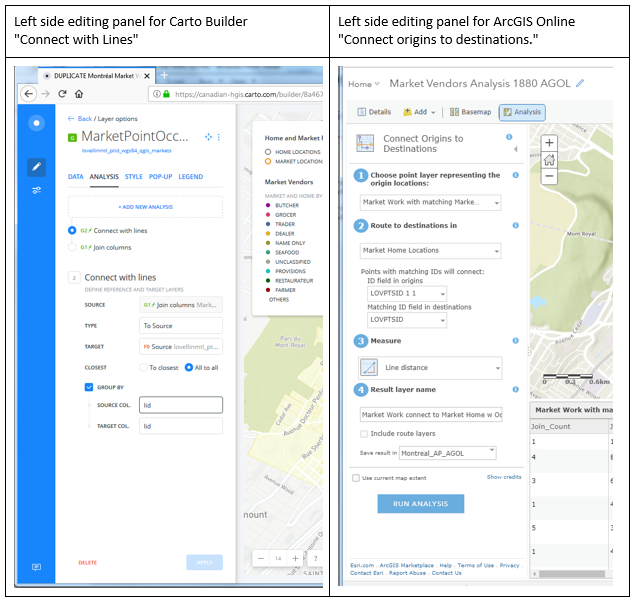
Mapbox fournit un certain nombre d’outils faciles à utiliser pour la gestion des cartes et des données en ligne ainsi que pour la composition des cartes, comme ArcGIS online. Cependant, il s’agit toujours d’un environnement de développement libre, offrant une personnalisation grâce à un certain nombre d’outils de développement (SDKs et APIs) qui sont résumés en ligne ici : https://www.mapbox.com/developers/. Pour les nouveaux utilisateurs de Mapbox, notre document de développement sur logiciel libre est disponible ci-dessous. Il fournit un « [traduction] aperçu du flux de travail dans Mapbox » (pages 3-4) que nous avons utilisé pour créer les cartes web du projet pilote.
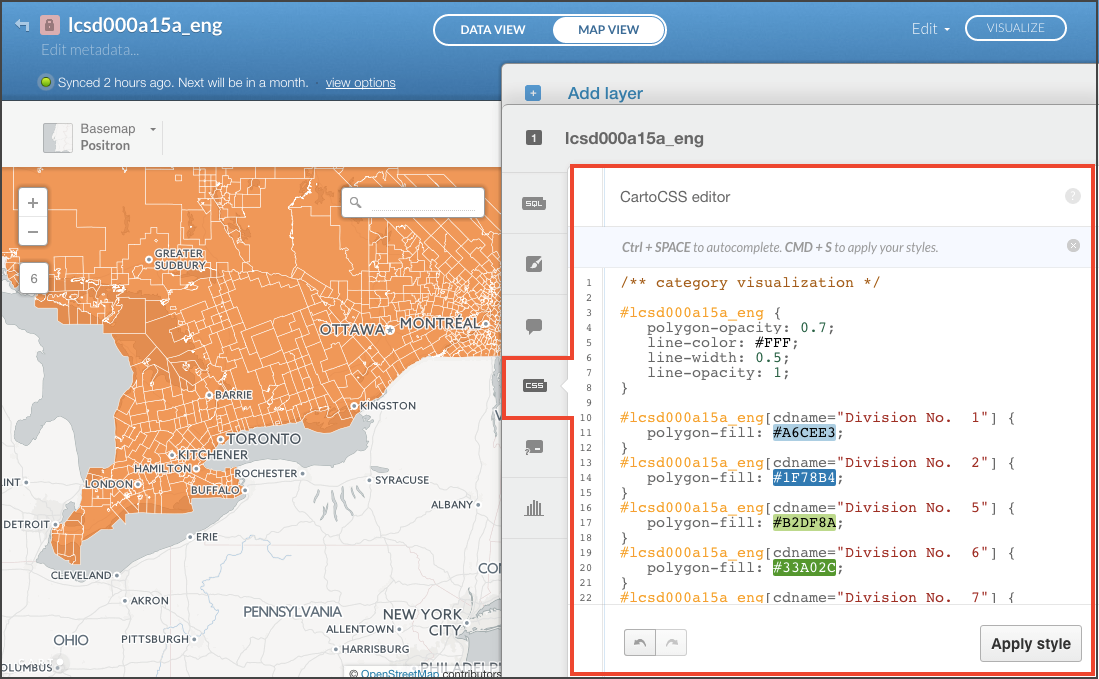
L’un des domaines où Mapbox est très flexible est la composition de la légende. Contrairement à ArcGIS, où les légendes sont faciles à inclure, mais plutôt inflexibles, Mapbox vous laisse le contrôle. Par conséquent, nous avons entrepris le défi de créer du code pour générer une légende basée sur le même tableau configuré pour la classification des données cartographiques.
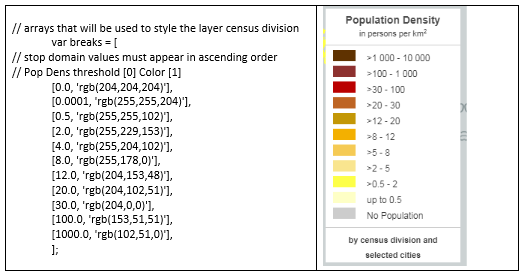
Par exemple, lorsqu’un tableau de couleurs est défini pour les classes choroplèthes, une légende est générée automatiquement qui hérite du jeu de symboles. Ceci est détaillé dans le document de développement avec logiciel libre sous « Data driven styling and automated legend creation », p. 12-15 et un gabarit est fourni sur GitHub.
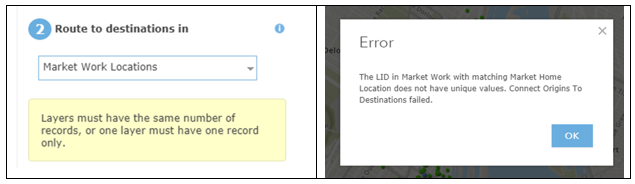
Pour les versions d’ArcGIS Online et de Mapbox, nous avons constaté que les améliorations de la vitesse d’affichage n’étaient pas aussi bonnes que nous l’espérions. Les polygones des divisions des recensements et les lignes sont complexes, même lorsqu’ils sont généralisés et optimisés pour le déploiement sur le web, et leur diffusion est plus lente que ce que l’on pourrait souhaiter. Nous avons expérimenté diverses solutions suggérées pour cela, dans les deux suites logicielles, mais nous n’avons rencontré que des améliorations modérées. Si vous avez des commentaires ou des suggestions à propos de ces questions, ou de tout autre aspect de conception des projets pilotes, n’hésitez pas à publier vos commentaires ci-dessous ou à contacter l’auteur à byron.moldofsky@gmail.com.
Pour plus d’informations sur le travail effectué sur ces projets pilotes de cartographie web, nous avons rendu disponibles nos documents de développement via les liens ci-dessous. Aussi, pour le logiciel libre, nous avons posté le code utilisé et quelques exemples de « modèles » sur GitHub.
LIENS VERS LA DOCUMENTATION
Cartes HACOLP de la « population par division de recensement », Document de développement avec logiciel libre (open-source)
Cartes HACOLP de la « population par division de recensement » Document de développement avec ArcGIS Online
Pour le code pour le site de cartographie libre, voir : HACOLP Github Open Source Repository